什么是维度表
在数据建模中,通常将包含了业务度量的数据称之为“事实”,而将产生度量的环境称之为“维度”。但是“维度”并非天然存在,而是需要通过业务分析来拆解,将相同的维度实体存储在一张表,这就是“维度表”。维度表可以看做数据分析的视角,比如时间、城市、用户等等,没有维度表的支撑而仅仅针对事实表进行分析的话,要么将难以分析(事实表、维度表糅合在一起),要么缺乏必要的分析指标导致结果相当单薄。如果说事实表就是红花,那么维度表就是绿叶,二者缺一不可。
但是,事实表和维度表也不一定是固定不变的,在不同业务团队的视角下,事实表和维度表可能是可以互换的。对于管理订单的团队,订单自然是事实表,而用户是维度表。但是对于负责社区运营的团队,用户也可以是事实表。
维度建模在hive的实践
本文将总结集中在hive中进行维度建模的经验和思考。
众所周知,hive的写入和读取都是以分区为单位。在这种情况下,进行维度建模的时候需要考虑些什么才能最大化利用或者说适应于hive的模式呢? 简单思考下大概是这两个问题
- 增量还是全量?增量的具体实现方式是什么?
- 增量的话,如何分区?以什么字段分区?
全量还是增量?
考虑到具体的业务和数据情况,不会有一种方式能够适用所有场景,我大致总结如下:
- 假如维度表数据量很小,例如城市的维度表就不会有多少条数据,自然全量覆盖是最佳选择。
- 假如数据量比较大
- 还需要考虑业务特性,如果每日增量占存量的比例很高(或者说所有的数据都经常更新,例如用户表),在极端情况下还是可能退化到近似全量的结果,增量的意义可以自行判断
- 如果每日增量的比例不高(或者说只有最新的数据才会更新,而过去的数据都不会或很少更新了,例如订单表),这时可以使用增量的方式
如何分区?
分区基本上两种方式,一是通过创建时间分区,二是通过对业务主键取hash来分区。两种方式都较为稳定,但是第一种方式对于业务数据略有要求,不一定所有的业务数据都是有create time的,而且会由于业务在特定时间的数据量较大而产生数据倾斜的情况。通过对业务主键取hash来分区(hash结果的前两位),可以得到相对均匀的分区,但是在极端情况下仍然会退化成为近似全量更新(假如需要更新的数据很多,几乎覆盖了所有hash分区。当然另一种办法是改进hash,例如将可能更新的数据都hash到一个分区,但是又掉回了数据倾斜的陷阱... ...)。
两种分区方式各有优略,看官可以根据自己的业务情况判断决策。通过Hive进行分区增量处理拉链表的代码实例可以参考Sharp ETL的实现。
没有银弹?
这么看下来,似乎没有一种方式可以放之四海而皆准啊。想要给特定情况的维度表进行建模需要的不仅仅是知道概念,还需要多一些经验和思考。简单粗暴的copy其他人或者其他项目的建模结果并不可取。
还没结束
如果当前考虑的不是hive的支持,那当然是极好的,无论是通过postgres或者其他RBDMS实现的小型数仓对于create、delete、update单条数据都是有较好的支持。如果是一些RDBMS的魔改版,例如YelloBrick作为魔改版的postgre,对于单条的操作有支持但不是很友好。如果是更现代的存储结构,例如Delta、Hudi、Iceberg这些,单条数据的近实时操作可以说都是他们的最大卖点了,毕竟他们的目标都是替代hive。
甚至Delta内建了History table来支持Time travel,听名字就大概知道这是一张保存了历史的表,并且可以通过时间或者版本号来查询当时的数据情况,官方文档说“Each operation that modifies a Delta Lake table creates a new table version. You can use history information to audit operations or query a table at a specific point in time.”。官方的使用sample是:
SELECT * FROM people10m TIMESTAMP AS OF '2018-10-18T22:15:12.013Z'
SELECT * FROM delta.`/tmp/delta/people10m` VERSION AS OF 123
而Hudi也有类似的功能,叫做Timeline,官方文档说“Hudi maintains a timeline of all actions performed on the table at different instants of time that helps provide instantaneous views of the table, while also efficiently supporting retrieval of data in the order of arrival”,可以说和Delta异曲同工了,官方的使用sample是:
create table hudi_cow_pt_tbl (
id bigint,
name string,
ts bigint,
dt string,
hh string
) using hudi
tblproperties (
type = 'cow',
primaryKey = 'id',
preCombineField = 'ts'
)
partitioned by (dt, hh)
location '/tmp/hudi/hudi_cow_pt_tbl';
insert into hudi_cow_pt_tbl select 1, 'a0', 1000, '2021-12-09', '10';
select * from hudi_cow_pt_tbl;
-- record id=1 changes `name`
insert into hudi_cow_pt_tbl select 1, 'a1', 1001, '2021-12-09', '10';
select * from hudi_cow_pt_tbl;
-- time travel based on first commit time, assume `20220307091628793`
select * from hudi_cow_pt_tbl timestamp as of '20220307091628793' where id = 1;
-- time travel based on different timestamp formats
select * from hudi_cow_pt_tbl timestamp as of '2022-03-07 09:16:28.100' where id = 1;
select * from hudi_cow_pt_tbl timestamp as of '2022-03-08' where id = 1;
当然,Iceberg也不会落后,这个功能也叫Time travel,官方sample:
-- time travel to October 26, 1986 at 01:21:00
SELECT * FROM prod.db.table TIMESTAMP AS OF '1986-10-26 01:21:00';
-- time travel to snapshot with id 10963874102873L
SELECT * FROM prod.db.table VERSION AS OF 10963874102873;
更进一步
实际上如果你一定要使用hive,又不想受限于hive的分区粒度读写。那么还有另一种办法,将Delta、Hudi、Iceberg注册到hive metastore,这样就可以通过hive来读写这张表了。只不过有一个缺点,我查询文档后发现Iceberg支持通过hive sql进行time travel,Hudi也支持通过hive sql进行time travel,Delta则尚不支持。
传统History table与Time travel的对比
传统的History table往往会通过诸如start_time, end_time来判断该条数据是否在生效时间区间,通过is_latest来判断是否是最新的数据。麻烦的点在于这几个字段可能不同的team甚至不同的表叫法都不一致,甚至会出现同样名字含义完全不同的字段(例如,is_active是什么含义?可能大家都有不同的看法)。实际使用中与事实表join的时候往往需要增加is_latest=true的判断,例如:
select ... ...
from dwd.t_fact_order fact
inner join dim.t_dim_product dim
on fact.product_id = dim.product_id
and fact.is_latest = '1';
而使用Time travel的时候则完全不需要考虑start_time, end_time等等额外字段,因为实际上存储引擎会将版本和变更时间等信息额外记录,不需要在表结构上额外操作。这样有一个好处就是这些字段都是透明且一致的,更不易出错。缺点大概是不一定能够满足所有需求,不能定制化。
实际用法应该类似:
select ... ...
from dwd.t_fact_order fact
inner join dim.t_dim_product TIMESTAMP AS OF date_sub(current_date(), 1) dim
on fact.product_id = dim.product_id;
注意⚠️
实践中无论是对于Hive的分区级别读写还是Delta、Hudi、Iceberg的行或者分区级别读写都会遇到并发的问题,下面尝试简单总结一下它们的锁机制。
Hive Concurrency Model
Hive 内部定义了两种类型的锁:
- 共享锁(Share)
- 互斥锁(Exclusive)
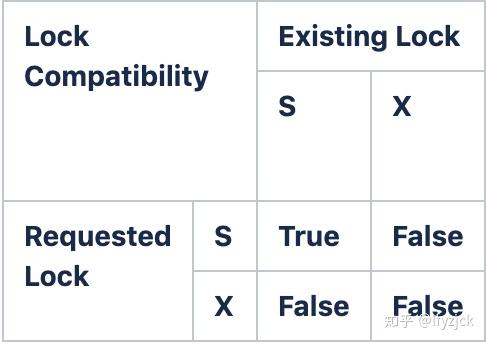
锁的基本机制是:
- 元信息和数据的变更需要互斥锁
- 数据的读取需要共享锁
乐观并发控制
剩下三位选手无一例外都选择了乐观并发控制:
乐观并发控制的大体流程分为以下三个步骤:
- Read: 读取最新版本的数据,作为一个数据集的一个 snapshot,然后定位需要改变的文件
- Write: 在上一步read 操作checkout 出来的版本上写入新数据
- Validate and commit: 在提交之前,检测是不是有其他以及提交的操作变动的文件,和本事务变动的文件有冲突,如果没有冲突,本次staged 的changes 就提交,产生一个新的数据集版本,如果有冲突,就会抛出一个并发修改异常,放弃修改。
乐观并发控制没有实际加锁,所以没有额外开销,也不错出现死锁问题,适用于读多写少的并发场景,因为没有额外开销,所以能极大提高数据库的性能。 乐观并发控制不适合于写多读少的并发场景下,因为如果出现很多的写冲突,就会导致数据写入要多次等待重试,在这种情况下,其开销实际上是比悲观锁更高的。
以上~
Original link:https://izhangzhihao.github.io//2022/10/30/维度表建模小结/